After missing one year, I was very excited to visit Koli again. After I had booked my travels, Miranda Parker asked me to join the doctoral consortium as a discussant. Change of plans, but this lead to a much more fulfilling experience!
Doctoral Consortium
After an early arrival to Joensuu on Monday, the Koli experience was kicked off with the doctoral consortium on Tuesday and Wednesday. Lead by Miranda Parker, and together with Claudia Szabo and Nick Falkner, we drilled the students on clarity of their explanation and strength of their pitches. We also played with tarot research cards, which exposed the students to new ideas and methods. It even gave us discussants new ideas for reseach questions and methods.
 Thanks to Afonso for the picture.
Thanks to Afonso for the picture.
We had a lot of fun together (at least I think so), and connections and friendships were built over the course of the DC and the rest of the conference.
Thursday
On Thursday we travelled from Joensuu to Koli on a fully packed bus. We had a little time to do some work or be a social butterfly, have lunch, and then the conference began.
We started this 25th iteration of Koli with most of the attendees present. The opening session revealed 166 papers were submitted, of which 48 were accepted (29%), and 10 out of 24 posters were accepted.
Papers I found the most interesting
The first session was kicked of by Eduardo Carneiro Oliveira, who discussed their paper on behavioral patterns they identified in student-LLM conversations during three (optional) code refactoring tasks. They found six patterns:
- Delegator. The student does not try the exercise themselves, and also does not edit the LLMs generated code, but takes it for full truth.
- Starter. This student starts without the LLM, but later asks specific questions for help.
- Fine-tuner. This student uses the LLM to edit code, but not in ways related to refactoring. The student does not have a conversation with the LLM, but instead edits the code themselves before submitting.
- Navigator. This student has long conversations with the LLM, incrementally building a code solution. The behavior resembles pair programming.
- Challenger. This student tries to tackle the problem themself by thinking it through, and then poses challenges to the LLM to see whether they identify the same opportunities.
- Soloist. This student does not use the LLM, or only for tasks unrelated to problem solving.
It would be interesting to see if these patterns generalize to other types of tasks! Some of the patterns did come up in other people's presentations later during Koli.
The next paper was on SQL queries in the era of genAI, presented by Antti Laaksonen. They have a lot of log data of queries from the past years, from before large-scale adoption of genAI. From this, they identified a few very clear pattern changes in terms of query contents. For example, newer queries have longer lines, as well as long aliases of multiple words connected in various ways. Newer queries also more often utilized the WITH clause, which was not part of the educational material. On the other hand, the correctness of the assessment has been constant over all those years. Overall, it seems like you would be able to detect AI based on these observations, but although that would be super valuable, it would not be ethical to judge that dimension purely due to deviation from the mean. On the other hand, these pattern changes do lead to increased readability, so if this is something students pick up on when they write their own queries, AI use for query formulation can have a positive effect.
In session 2 on Teaching practices, I liked the paper presented by Steven Bradley. Their team investigated the proceedings of the Computing Education Practice (CEP) conference in terms of the contextualization of the papers. They drew parallels to Marco Polo (who wrote elaborate exotic descriptions putting himself in the middle of all) and Maria Sibylla Merian (who wrote descriptions in context, taking into account the natural habitat). They found that the papers at CEP are mostly (experience) reports, in contrast to half of the papers at ITiCSE and Koli, and less than 10% at ICER. The problem is that not all of these reports are written as Maria, which reduce their generalizability and reproducability. So, the call to action is, if you do write an experience report, try to incorporate as much of the context as possible, and try to link theory and practice.
 Slide courtesy of Steven Bradley.
Slide courtesy of Steven Bradley.
Some other thought-provoking ideas I heard today:
- Sadia Sharmin and Yohan Kim investigated changes to education during COVID-19 from the perspective of Pedagogy of Kindness. One of the things we should not be throwing out with the bathwater is compassion and trust towards our students.
- Claudia Szabo discussed the connection between Parsons problems and theory. Of the list of 21 theories compiled earlier by Lauri Malmi, they found 13 and 10 theories/models linked to the concept of Parsons problems across two methodologies. Unfortunately, most of these were only name-dropping the theory and not actually utilizing them in their paper. I figure I probably have done this before too, but I'm really trying to do better in newer papers.
- Brent Reeves and their team shared their vision on computing. It has been a long time since we started to teach programming on the abstraction level of assembly, instead we use levels of abstraction such as Java or Python. This is not a new idea, people were already talking about universal languages in 1966. However, their suggestion is that maybe now we are at the point that this universal language should be Natural Langauge.
The day ended with the lighting talks and posters of the Doctoral Consortium students.
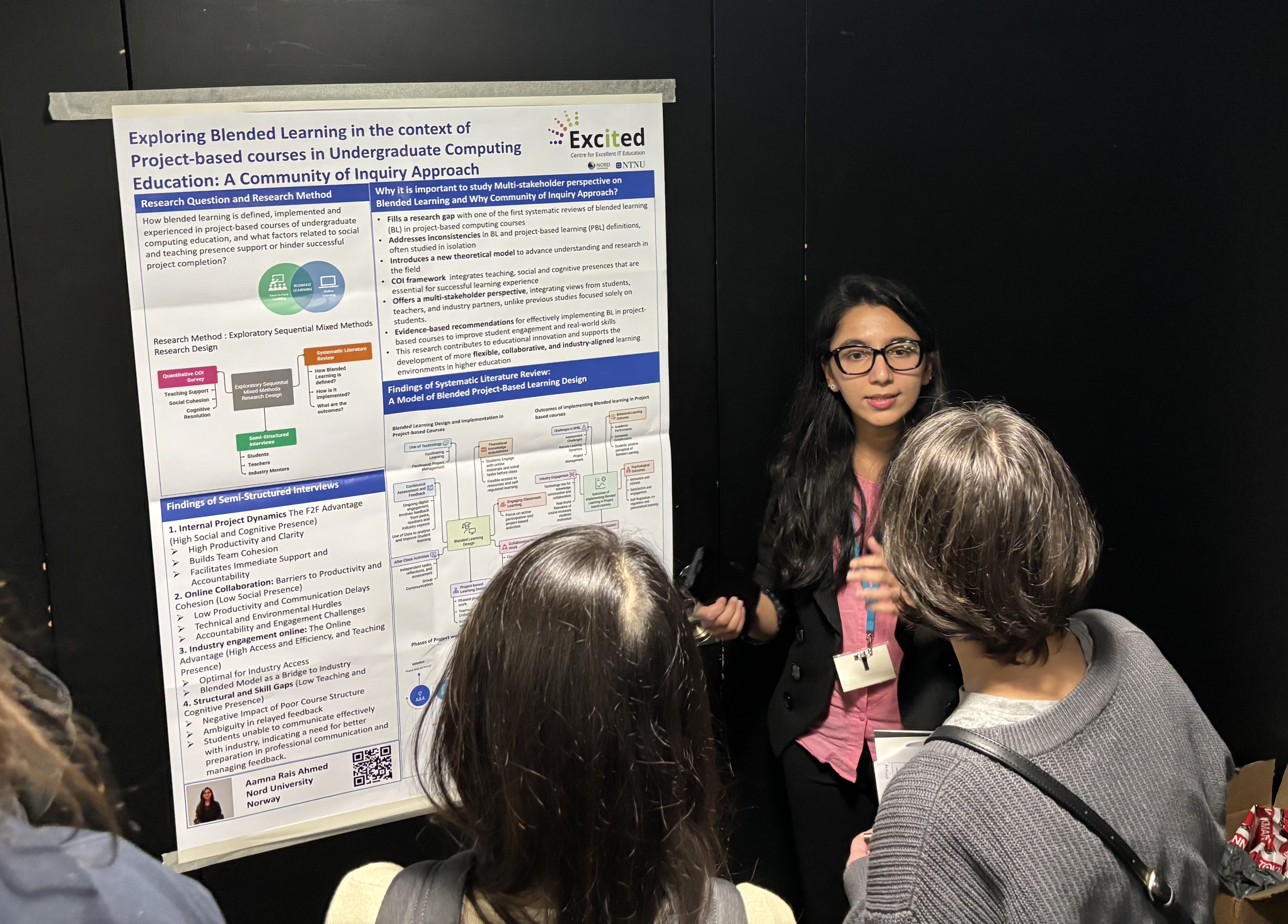 Aamna is presenting her work.
Aamna is presenting her work.